
Context engineering is the systematic process of designing, building, and optimizing the information pipeline that provides a large language model (LLM) with the precise, relevant data it needs to perform a task accurately. It’s the critical discipline that transforms a powerful but generic AI into a specialized, reliable expert.
Think of an LLM as a world-class surgeon. A prompt is the command to “perform the surgery.” Context engineering is the entire support system: the patient’s medical history, real-time vital signs, MRI scans, and the specific surgical tools laid out in perfect order. Without this system, the surgeon’s skill is useless.
This is the central challenge in AI today. Industry data reveals that over 40% of AI project failures stem not from a flawed model, but from providing poor or irrelevant context. Context engineering directly addresses this multi-billion dollar problem.
Understanding What Context Engineering Is
While most people have heard of “prompt engineering”—the skill of writing a perfect question or command for an AI—context engineering is a much broader and more technical discipline. It recognizes that the quality of an AI’s output isn’t just about the wording of a single prompt. It’s about the quality, relevance, and structure of the information the AI is given to work with.
In short, it’s about architecting the entire information environment an AI operates within, ensuring it has everything it needs to succeed.
From Prompting to Architecting
Context engineering is rapidly becoming one of the most critical skills in the AI domain, representing a significant leap in complexity and impact from prompt engineering. Unlike prompt engineering, which focuses on crafting a single static instruction, context engineering involves designing dynamic systems that automatically find, filter, and deliver the right information and tools to an AI agent, precisely when needed.
This shift was driven by a clear business need. As AI evolved from simple chatbots to complex, multi-agent workflows, a major bottleneck emerged. It became evident that simply asking a better question isn’t enough if the AI lacks the foundational knowledge to answer it. Great AI performance now depends on getting the right data, in the right format, to the model at the right time. That’s the exact challenge context engineering is built to solve. If you want to dive deeper into this emerging field, you can explore these expert insights on context engineering .
Context Engineering vs Prompt Engineering At a Glance
The easiest way to understand what is context engineering is to see how it stacks up against the more familiar concept of prompt engineering. One is about crafting a single message; the other is about building the entire data delivery system that makes those messages powerful.
Here’s a clear comparison that highlights the fundamental differences.
Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
Primary Goal | Write the best possible instruction for a single AI interaction. | Build a system that dynamically provides the best information to the AI. |
Scope | Narrow and specific to a single query or task. | Broad, covering the entire data pipeline and AI environment. |
Analogy | A skilled lawyer asking the perfect question in court. | The entire legal team preparing all the case files and evidence. |
Focus | The "what" and "how" of a single command. | The "who," "what," "where," and "why" behind the entire task. |
Key Skills | Creative writing, linguistics, understanding model behavior. | Systems design, data architecture, retrieval strategies, software engineering. |
This table shows a fundamental shift in how we approach AI development. Prompt engineering is a tactic used in a specific moment. Context engineering is the overarching strategy that ensures every one of those moments is effective. It’s the infrastructure that enables high-quality, consistent performance, moving us beyond one-off successes to build truly dependable AI applications.
Why Accurate Context Is the Secret to Great AI
Even the most advanced AI models are not omniscient. Their “intelligence” is a direct function of the information they are given at inference time. An AI without the right context is like a world-class chef trying to cook a gourmet meal from a mystery box of random ingredients. No matter how skilled they are, the result will be a mess. This is the single biggest hurdle in building dependable AI today.
In fact, poor context is the root cause of most AI failures. When you flood a model with a mountain of irrelevant data just to include a few key facts, you are actively setting it up for failure. This is especially true for complex, multi-step reasoning tasks, where a single piece of irrelevant information can derail the entire process.
The “Lost in the Middle” Problem
A primary challenge is a well-documented flaw in LLM architecture known as the “lost in the middle” problem. Extensive research shows that models with large context windows pay disproportionate attention to information at the very beginning and very end of the provided context. Critical details buried in the middle are frequently overlooked or completely ignored.
Think of it like giving an AI a 100-page report and asking for a specific number on page 57. The model is statistically likely to get distracted by the introduction and conclusion, completely glossing over that one crucial piece of data. This cognitive blind spot leads to common AI failures:
-
Hallucinations: The AI can’t find the real answer in the context, so it invents one. The output sounds plausible but is factually incorrect.
-
Irrelevant Responses: The model latches onto an unimportant detail and goes off on a tangent, providing an answer that fails to address the user’s query.
-
Broken Logic: The AI begins a chain of reasoning but loses track of a key piece of information that was “lost in the middle,” leading to an incomplete or illogical conclusion.
This isn’t just an academic curiosity; it has direct business consequences, leading to wasted compute cycles, buggy applications, and a fundamental lack of trust in AI tools.
Bigger Isn’t Always Better
You might think the solution is to use the latest large language models (LLMs) with their massive context windows, some of which can handle over 128,000 tokens. However, research and practical application have shown that throwing more data at the problem doesn’t fix it. In fact, it often makes things worse.
One pivotal study found that indiscriminately stuffing the context window can degrade a model’s performance by 15–20%. The AI simply gets overwhelmed by the noise. This is where context engineering provides a solution. It isn’t about brute force; it’s about precision. The goal is to carefully select and structure the most relevant 10–30% of the available data for any given task. This focused approach not only improves accuracy but also leads to 25–40% faster response times by reducing the token load on the model. If you want to dive deeper into the numbers, you can read more about these context engineering findings and see the data for yourself.
This brings us to a core principle of modern AI development: The goal isn’t to give the AI more information, but to give it the right information. Precision beats volume, every single time.
Ultimately, effective context engineering acts as an intelligent filter. It shields the AI from information overload and ensures it only receives what is absolutely essential to get the job done. This is how you transform a powerful but unpredictable model into a reliable and genuinely helpful partner.
How a Context Engineering System Works
To understand what context engineering is, think of a master chef preparing for dinner service. They don’t just randomly pull ingredients from the fridge. They meticulously select, measure, and arrange every component before cooking begins. A context engineering system does the exact same thing for information, ensuring the AI receives a perfectly prepared “meal” of data.
This process is typically broken down into four distinct stages. Each step is crucial, transforming raw, unstructured data into the precise, useful context an AI needs to perform at its peak. It’s a carefully choreographed flow of information, from a simple user query to a genuinely intelligent AI response.
This infographic captures that chef analogy perfectly—showing how the system preps all the right ingredients (labeled data, in this case) to serve up to the AI.
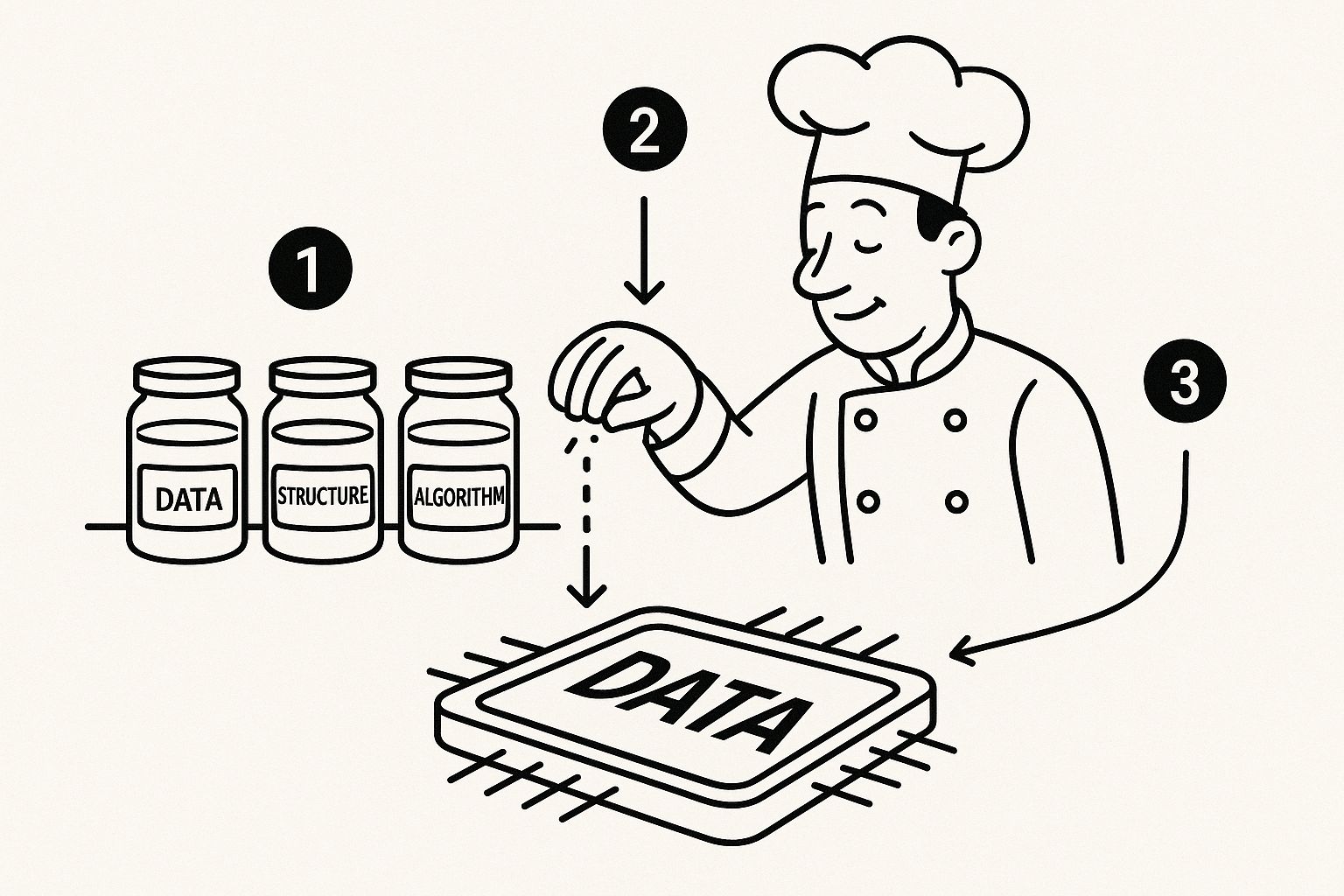
Just like the chef organizes everything for a recipe, the system structures all the necessary data to generate an intelligent, accurate answer.
Stage 1: Data Ingestion and Processing
It all begins with Data Ingestion. This is where the system actively gathers raw information from a wide variety of sources.
That data can come from anywhere:
-
Internal Documents: Your company’s internal wiki, technical manuals, or project files.
-
Databases: Structured information from SQL or NoSQL databases, like customer records or product inventory.
-
APIs: Live data feeds from other services, such as weather forecasts or stock market prices.
-
Conversation History: Past user interactions to understand recurring questions and user intent.
This raw data is unusable for an AI in its native state. That’s where the Processing phase comes in. The system cleans the data, removes irrelevant details, corrects errors, and standardizes the format. For text, this almost always involves “chunking”—breaking down large documents into smaller, semantically coherent pieces that are easier for an AI to digest.
Stage 2: Data Indexing
Once the data is clean and chunked, you need a way to find it efficiently. That’s Data Indexing. Imagine creating a hyper-detailed, searchable index for a massive library. The AI can then pinpoint the exact information it needs in milliseconds.
The core technique here is creating vector embeddings. This process uses a model to convert text chunks into numerical representations (vectors) that capture their semantic meaning. Concepts that are similar are placed closer together in a high-dimensional space. These vectors are then stored in a specialized vector database, which is optimized for ultra-fast similarity searches.
Stage 3: Dynamic Retrieval
This is where the system becomes dynamic. When a user asks a question, the Dynamic Retrieval process activates to find the most relevant information for that specific query. The system converts the user’s question into its own vector and then searches the vector database to find the data chunks with the most similar vectors.
This is the heart of a technique called Retrieval-Augmented Generation (RAG), a cornerstone of modern context engineering. It augments the AI’s general knowledge with fresh, relevant facts pulled from an external source at the moment of the query.
But it doesn’t just stop there. A sophisticated system often uses a re-ranking step, where another model evaluates the initial search results to ensure only the absolute best, most relevant pieces of information get passed on.
Stage 4: Context Assembly
Finally, we arrive at Context Assembly. The system takes the retrieved data chunks and carefully arranges them alongside the user’s original prompt. This isn’t a simple copy-and-paste job. The information is structured and formatted in a way that is optimized for how the Large Language Model (LLM) processes information, often placing the most critical facts at the beginning or end to avoid the “lost in the middle” problem.
This final package—containing the user’s question and the curated context—is sent to the AI. Because it has been handed this pre-processed, highly relevant information, the AI is set up for success. It doesn’t have to guess or rely on outdated knowledge. It has the exact “ingredients” it needs to generate a response that’s accurate, helpful, and completely in context.
The Context Engineer’s Toolkit: Key Techniques
Let’s move from high-level architecture to the specific, field-tested techniques a context engineer uses to build the information pipelines that make AI systems genuinely smart.
Mastering these methods is what separates a clunky chatbot from an intelligent system that can reason, act, and remember. Each one solves a very particular problem, whether it’s stopping an AI from making things up or giving it the power to interact with other software.
Retrieval-Augmented Generation (RAG)
If one technique defines modern context engineering, it’s Retrieval-Augmented Generation (RAG). This is our primary weapon against AI “hallucinations” and stale, outdated knowledge. RAG connects a Large Language Model (LLM) to a reliable, external source of information, forcing it to “cite its sources” before generating a response.
Think of it as an open-book exam. Instead of forcing the AI to recall an answer from its vast, static memory, RAG allows it to look up relevant information in a trusted database first. For example, a customer support bot can use RAG to pull the latest product specs from a technical manual before answering a user’s question, ensuring the information is always accurate.
Function Calling and Tool Use
While RAG gives an AI knowledge, Function Calling (or Tool Use) gives it agency. This technique enables the LLM to interact with external software and APIs. It’s what transforms a passive chatbot into an active agent that can perform tasks in the digital world.
Imagine a travel assistant AI. With function calling, it can:
-
Check flight availability by calling an airline’s API.
-
Look up hotel prices by querying a booking service.
-
Make a dinner reservation by interacting with a restaurant’s system.
Suddenly, the AI isn’t just a conversationalist; it’s a doer. Providing the right tools is just as crucial as providing the right information because it empowers the AI to take action and solve real-world problems.
Managing Conversational Memory
Long conversations present a significant challenge: how does an AI maintain context over multiple turns? As a chat progresses, the context window fills up, and you run into the “lost in the middle” problem, where the model starts ignoring crucial details buried in the conversation history.
A core task of context engineering is deciding what an AI needs to remember versus what it can safely forget. This is critical for preventing “context poisoning,” where an irrelevant fact from earlier in a conversation can derail everything that follows.
Engineers use several strategies to manage this:
-
Short-Term Memory: Creating a running summary of the recent back-and-forth to keep immediate context fresh.
-
Long-Term Memory: Storing key facts or user preferences (e.g., “this user prefers non-stop flights”) in a vector database to be retrieved when needed in future chats.
-
Context Trimming: Intelligently cutting out older, less relevant parts of the conversation to make room for more important information.
Context Re-Ranking and Filtering
Finally, retrieving relevant information isn’t always enough. You also have to ensure the AI pays attention to the most important pieces. Context Re-Ranking is that last-mile refinement where a second, lighter-weight model or algorithm sorts the retrieved data by relevance before it’s sent to the LLM.
This step is incredibly powerful. Given the LLM’s bias toward the beginning and end of a prompt, a context engineer can use re-ranking to strategically place the most critical facts in those prime locations. This guides the AI’s reasoning and nudges it toward a more accurate conclusion. It’s the final polish that ensures the AI doesn’t just have the right data, but actually uses it effectively.
To help tie all this together, here’s a quick summary of these core techniques and where you’d typically see them in action.
Context Engineering Techniques and Their Applications
Technique | Primary Goal | Example Use Case |
|---|---|---|
Retrieval-Augmented Generation (RAG) | Grounding AI in factual, up-to-date information to prevent hallucinations. | A corporate chatbot answering employee questions using an internal knowledge base. |
Function Calling / Tool Use | Enabling AI to interact with external systems and perform actions. | A virtual assistant booking a flight by calling an airline's API. |
Conversational Memory Management | Maintaining coherent, long-running conversations without losing key details. | A personal AI tutor that remembers a student's progress across multiple lessons. |
Context Re-Ranking & Filtering | Prioritizing the most relevant information to improve the model's focus and accuracy. | An AI research assistant that highlights the most critical findings from a dozen academic papers. |
As you can see, each technique solves a distinct piece of the puzzle, and they are often used together to build sophisticated, reliable, and truly helpful AI applications.
Watch These Techniques in Practice
Ready to see RAG, function calling, and context management working together in a real development workflow? This video demonstrates how the Context Engineer MCP implements these principles:
Follow along as we show context-aware planning sessions, automatic PRD generation, and how to feed the right amount of context at the right time to AI coding agents like Cursor, Claude Code, and Windsurf.
The Business Impact of Getting Context Engineering Right
Beyond the technology, what does context engineering actually deliver for a business? This is where AI transitions from a novel experiment to a strategic asset with a measurable return on investment. Getting the context right directly impacts your bottom line by improving efficiency, reducing risk, and creating new revenue opportunities.
The financial stakes are enormous. Reports suggest that mismanaging AI context costs companies billions annually in failed automation projects and operational inefficiencies. Conversely, businesses in sectors like finance and e-commerce that master context-aware AI have seen customer retention jump by 18–27% while cutting operational costs by 12–20% per year. It’s no surprise there’s a growing demand for context engineers who can deliver these kinds of results.
Driving Revenue and Customer Loyalty
In the competitive world of e-commerce, context is the key to personalization at scale. Think about a shopping assistant that moves beyond simple keyword searches. By feeding it real-time inventory data, a user’s browsing history, and past purchase behavior, you create a genuinely personal shopping guide.
This context-rich assistant can:
-
Recommend products that are not just a good fit but are also in stock and available for immediate shipping.
-
Suggest complementary items based on what a shopper has previously bought, increasing the average order value.
-
Understand nuanced queries like, “find me a dress like the one I bought last summer, but in blue.”
This level of personalized service was once exclusive to luxury boutiques. Context engineering allows you to offer it to millions of online shoppers, turning casual visitors into loyal customers.
Mitigating Risk and Ensuring Compliance
For financial institutions, the risks associated with AI errors are immense. A single fraudulent transaction or compliance breach can result in devastating losses and severe regulatory penalties. Context engineering provides the AI systems that stand guard with the real-time information they need to make accurate decisions.
A fraud detection AI, for example, can be fed a live stream of data, including a customer’s transaction history, current geolocation, and typical spending patterns. When an anomalous transaction occurs, the AI has the full context to differentiate between a legitimate purchase on vacation and a fraudulent withdrawal, stopping financial crime in its tracks. Similarly, compliance bots can validate actions against an up-to-the-minute database of regulations, ensuring adherence to legal standards.
This isn’t just about preventing losses; it’s about building trust. When customers feel confident their assets are protected by intelligent, context-aware systems, their loyalty to the institution deepens.
Enhancing Diagnostics and Patient Care
In healthcare, providing the right information at the right time can be a matter of life and death. Context engineering is helping clinicians make faster, more accurate diagnoses by giving AI models a holistic view of the patient. An AI diagnostic tool can analyze a patient’s symptoms in conjunction with their entire medical history, lab results, genetic data, and even relevant family history.
By pulling in context from the latest medical journals and clinical trials, these AI systems can identify rare conditions or suggest treatment protocols a human doctor might overlook. The AI becomes a valuable partner, augmenting the expertise of medical professionals and leading to better patient outcomes.
How to Get Started with Context Engineering
Getting started with context engineering is more accessible than you might think. You don’t need a PhD in data science; you need a solid foundation in software engineering and a structured plan. It begins with mastering a few core technologies and building a small, focused project.
First, you need to get comfortable with the basic tech stack. A strong command of Python is essential, as it’s the lingua franca of AI development. Next, you’ll need to understand how to work with Large Language Model (LLM) APIs from providers like OpenAI or Anthropic . Finally, you’ll need a working knowledge of vector databases like Pinecone or Chroma , which are fundamental to the retrieval process.
Building Your First Project
The most effective way to learn is by building. A classic first project is creating a Q&A bot that can answer questions about your own set of documents. This exercise forces you to implement every stage of a context engineering system.
Here’s a high-level game plan:
-
Ingest and Process: Choose a few documents (PDFs or text files). Write a Python script to read them and break them down into smaller, meaningful chunks.
-
Index: Use an LLM’s embedding API to convert these text chunks into vector embeddings. Store these embeddings in a local vector database.
-
Retrieve and Assemble: When a user asks a question, convert their query into a vector as well. Search your database for the text chunks with the most similar vectors. This collection of relevant information becomes the context for your prompt.
-
Generate: Send the final package—the user’s question plus the retrieved context—to an LLM. The model will then generate an answer grounded in the facts from your documents, not just its general knowledge.
Key Frameworks to Explore
You don’t have to build these systems from scratch. Powerful open-source frameworks provide the building blocks you need.
-
LangChain : A comprehensive framework for chaining LLMs with other data sources and tools. It’s ideal for building complex, multi-step AI workflows.
-
LlamaIndex : A data-centric framework that excels at the ingestion, indexing, and retrieval parts of the pipeline. It is specifically designed to make building powerful RAG applications as simple as possible.
Ultimately, context engineering isn’t just a new job title; it’s a fundamental mindset for building AI that works reliably. It’s about shifting from being a prompt writer to an information architect—designing the entire data ecosystem that enables an AI to perform its job with accuracy and consistency.
The Context Engineering MCP in Action: Powering AI Coding Agents with Perfect Context
A clear example of context engineering in practice is software development. The Context Engineering MCP (Model Context Protocol) shows how a well-structured information pipeline can help an AI coding agent understand an entire project instead of reacting to isolated prompts.
When developers work with coding agents, most mistakes come from missing or fragmented context. The model can see pieces of code but not the relationships between them. It does not know how the system is organized, why a feature exists, or what the final goal is. The Context Engineering MCP solves this by collecting and maintaining every layer of information the AI needs to reason correctly.
The process begins with a complete codebase analysis. The MCP scans the repository, identifies dependencies, and builds a Code Context Graph that maps how all components, APIs, and data flows connect. This becomes the agent’s internal map of the system and allows it to reason about structure, not only syntax.
From this foundation, the MCP creates several documents that mirror how a real engineering team would plan a project. Each serves a specific purpose and gives the AI a different form of understanding.
Product Requirements Document (PRD)
The PRD defines the why and the what. It explains the goal of a feature, the problem it solves, the users it affects, and the success criteria.
For example, in a development project, the PRD might describe the goal of adding a real-time notification system, the reason users need it, and the expected performance metrics such as latency or delivery reliability.
The PRD keeps every technical decision connected to its purpose. When information is missing, the Context Engineer MCP automatically asks clarifying questions such as:
“Who is the end user of this feature?”
“What is the primary action the user should be able to perform?”
“How will we know when this feature is working as expected?”
These questions are guided by the existing project structure. If the system detects established conventions, it adapts its inquiries accordingly:
“I see that your authentication service uses event-driven handlers. Should the notification system follow the same approach?”
“Your APIs use a /v2/ namespace. Should the new endpoints use the same versioning pattern?”
By referencing existing patterns, the MCP helps maintain internal consistency across all new development.
Technical Blueprint
The Technical Blueprint defines the how. It translates the PRD’s intent into a concrete, structured plan that includes the system architecture, data flows, dependencies, and integration notes. Its goal is not to give the agent every detail but to provide the minimum viable context required to act safely within the existing system.
Too much context can be as harmful as too little. If the AI receives an overload of unrelated information, it becomes harder for it to focus on the correct logic paths, leading to confusion or code that unintentionally breaks existing functionality. The Technical Blueprint prevents this by giving the agent a focused, scoped view of the architecture that is directly relevant to the task at hand.
To achieve this, the MCP introduces Current vs Target Architecture Charts inside the Technical Blueprint.
• The Current Architecture shows how the system works today: the active data flows, dependencies, and integration points.
• The Target Architecture shows the state the system should reach once the new feature or change is implemented.
This two-layer structure gives the AI a precise understanding of what must remain untouched and what is expected to change. The agent can then plan modifications in a way that extends the system without breaking it.
When additional clarity is needed, the MCP asks context-rich questions that reflect both the blueprint and prior design patterns:
“The message queue currently handles logging events through Kafka. Should the notification events be published to the same topic or a new one?”
“I see that caching is handled through Redis in the existing architecture. Do you want to maintain that pattern for this module?”
These questions keep the agent’s focus narrow, precise, and safe within the current architectural boundaries.
Tasks Document
The Tasks document defines the execution. It breaks the work into small, clear steps with specific goals and acceptance criteria. Each task lists related files, linked PRD items, and relevant sections of the blueprint.
Continuing the example, these tasks could include integrating the message queue, building the user preference API, and creating the front-end notification component. Each task connects back to the blueprint and PRD, forming a continuous chain from purpose to code.
Before writing or refactoring, the MCP retrieves all related context and combines it into a single package for the AI. It then validates the next step by comparing it with similar implementations in the project’s history. If differences appear, it asks for confirmation:
“The existing UI components use a custom hook for state management. Do you want to follow the same pattern here?”
“The API responses for user data include a status field. Should notifications return the same field?”
By using this method, the MCP ensures that the AI makes informed, consistent decisions that respect both the project’s structure and its design philosophy.
How These Documents Work Together
The three documents form a layered structure that gives the AI complete situational awareness.
Layer | Document | Purpose | Type of Context | Resulting AI capability |
|---|---|---|---|---|
Intent | PRD | Defines vision and goals | Strategic | Keeps output aligned with objectives |
Design | Technical Blueprint | Provides structured context of current and target system | Structural | Enables accurate changes without breaking architecture |
Execution | Tasks | Lists concrete actions and completion criteria | Operational | Produces consistent, traceable code generation |
Together, these layers allow an AI coding agent to operate with a full yet focused understanding of both the product and its technical environment. The MCP continuously maintains this context, validating assumptions, identifying existing patterns, and refining what the agent sees before every action.
Through this process, the AI develops a working awareness of the project that remains accurate, efficient, and aligned with the system as it evolves.Frequently Asked Questions About Context Engineering
Frequently asked questions about Context Engineering
Let’s address some of the most common questions about context engineering to clarify its role and challenges.
Is This Just a Fancy Name for Prompt Engineering?
No, they are distinct disciplines. Prompt engineering focuses on crafting the perfect single instruction for an AI. Context engineering is about building the entire automated system that finds and delivers the right background information to the AI before it even processes the prompt.
A simple analogy: a prompt engineer is a skilled lawyer asking a brilliant, pointed question in court. The context engineer is the entire legal team that spent months gathering evidence and organizing case files, making that one brilliant question possible and effective.
What Are the Biggest Challenges in Building These Systems?
Two primary challenges consistently emerge: data quality and system latency.
First, the “garbage in, garbage out” principle applies with full force. If the source data is inaccurate, outdated, or poorly structured, the AI’s output will be unreliable, no matter how sophisticated the model or retrieval system is.
Second, latency is a critical factor. Users expect near-instantaneous responses. A system that takes 30 seconds to retrieve the correct context for a simple query is commercially unviable. Engineers must design retrieval systems that can search vast amounts of data and return the most relevant information in milliseconds, which is a significant technical challenge.
Do I Need to Be a Data Scientist to Get Into This Field?
Not necessarily. The skillset for context engineering often aligns more closely with that of a software or systems engineer.
Proficiency in Python, experience with APIs, and a solid understanding of data structures and databases (especially vector databases) are key. Frameworks like LangChain and LlamaIndex abstract away much of the complex data science.
More than any specific credential, you need a systems-thinking mindset. The job is about designing and building the robust information pipelines that make AI genuinely smart and useful.
How Does the Context Engineering MCP Actually Work in Development Projects?
The Context Engineering MCP is a system that continuously builds and maintains structured context around a project. It performs a full analysis of the codebase and generates three core documents:
• The PRD defines goals and intent.
• The Technical Blueprint defines architecture and constraints.
• The Tasks Document defines the step-by-step execution plan.
Together, these create a living model of the project that the AI can query and update as work progresses. This ensures every generated feature, refactor, or improvement fits into the existing system without breaking it.
Why Does the Technical Blueprint Focus on the “Minimum Viable Context”?
Large Language Models perform best when given only the information they need. Too much context makes them lose focus and increases the chance of errors.
The Technical Blueprint gives the agent a clean, structured view of what matters most — the architecture, data flow, and interfaces that define how the system actually works.
Its Current vs Target Architecture Charts make this process even safer:
• The Current view describes the live system as it exists today.
• The Target view describes what it should look like after the planned change.
By comparing the two, the MCP ensures the AI modifies only what is intended, keeping the system stable while moving it forward.
What Makes the MCP’s Questions Different from Typical AI Prompts?
The MCP doesn’t ask generic clarifying questions. It generates context-aware questions that reference existing code and design patterns.
For example:
“I see you used a custom caching layer in the user service. Should the new notifications module follow the same structure?”
“Your other endpoints use a /v2/ namespace. Do you want this new API to stay consistent with that pattern?”
This allows the AI to reason within the established boundaries of the project instead of treating every task as a blank slate.
Can Context Engineering Be Applied Beyond Software Development?
Yes. The same principles apply to any field where AI needs structured, reliable information: finance, healthcare, education, manufacturing, and research.
In each case, the context pipeline defines what the AI sees and how it interprets it. Software development is simply the clearest example because its data and dependencies are already highly structured.
What Kind of Impact Can a Well-Engineered Context System Have?
A well-built context system dramatically improves output reliability, reduces error rates, and accelerates execution.
In development projects, teams report faster iteration, fewer regressions, and more predictable AI-generated code.
Across industries, businesses that invest in precise context pipelines see measurable gains in efficiency, consistency, and trust in their AI systems.
Ready to eliminate AI hallucinations and build complex software features with confidence? Context Engineering connects directly to your IDE to provide AI agents with the precise, real-time project context they need. Start building smarter and faster today. Get started at https://contextengineering.ai .