
Hypothesis-driven development (HDD) is a methodical approach to product creation that replaces guesswork with scientific rigor. Instead of building features on a hunch, teams formulate a testable hypothesis, build the absolute minimum required to test it, and use empirical data to drive decisions. This methodology is no longer a niche practice; industry reports indicate that over 90% of high-performing product teams leverage some form of hypothesis testing to de-risk their roadmaps and focus on customer value.
Why Guesswork Is Costing You More Than You Think

Many development teams operate as “feature factories,” churning through a predetermined backlog. This traditional model often relies on gut feelings, the loudest stakeholder’s opinion, or competitor mimicry. The consequences are predictable and costly: a study by the Standish Group revealed that over 50% of software features are rarely or never used, representing billions in wasted engineering hours and bloated, ineffective products.
Hypothesis-driven development flips this script. It reframes the goal from completing a checklist of outputs to achieving measurable outcomes through a continuous cycle of learning. By starting with a clear, falsifiable assumption, teams are forced to connect their daily work directly to customer value and business goals before a single line of code is written.
The Shift From Assumptions To Evidence
At its core, HDD is the scientific method adapted for the agile world of software development. Instead of getting mired in subjective debates about what might work, teams deal in objective data. This shift delivers significant advantages.
- Reduced Risk: By testing ideas with small, low-cost experiments, you avoid sinking months and budgets—often exceeding $100,000 for a single feature—into products nobody wants.
- Faster Learning: You discover what resonates with users in days or weeks, not quarters. This accelerates your ability to pivot or double down with confidence.
- Customer-Centricity: This process forces a laser-like focus on actual user problems, ensuring you build solutions that people truly need and value.
This approach moves teams from asking “Can we build it?” to the far more important question, “Should we build it?” An invalidated hypothesis isn’t a failure; it’s a valuable lesson that saves you an incredible amount of time and resources down the road.
Let’s break down the practical differences.
Traditional vs Hypothesis Driven Development
The table below highlights the fundamental shift in mindset between these two approaches.
| Aspect | Traditional Development | Hypothesis Driven Development |
|---|---|---|
| Starting Point | A list of features or requirements | A testable hypothesis about a user or business outcome |
| Primary Goal | Ship features on time and on budget | Validate or invalidate assumptions to maximize learning |
| Measure of Success | Output (e.g., features delivered) | Outcome (e.g., improved conversion, higher engagement) |
| View of Failure | A bug, a missed deadline, or a project cut | An invalidated hypothesis (which is seen as valuable learning) |
| Team Focus | “How do we build this?” | “Why are we building this, and how will we know if it works?” |
| Customer Feedback | Gathered late in the process, often after launch | Gathered early and continuously throughout the experiment |
The focus shifts dramatically from simply building stuff to building the right stuff. To truly get past the guesswork, you have to understand why relying on intuition alone is so risky and how to embrace data-driven decision making as a core team competency.
The Core Principles of Driving Development with Hypotheses

To make hypothesis-driven development effective, teams must internalize a few core principles. These aren’t complex rules but a mental framework for turning “what if” moments into decisions backed by real evidence.
The first, and most critical, principle is to formulate a clear, testable hypothesis. This isn’t a vague goal; it’s a precise statement that outlines a specific action, a target user group, and an expected, measurable outcome. This structure forces a direct link between a feature idea and a tangible business goal.
A robust hypothesis often follows this simple template: We believe that [doing this action] for [these specific people] will achieve [this measurable outcome].
Define Success Before You Start
With a hypothesis in hand, the next step is non-negotiable: define success metrics upfront. How will you know if your assumption was correct? This question must be answered before development begins.
Your metrics must be specific and quantifiable. Forget vague goals like “improve engagement.” Instead, define success as something concrete, like “a 15% increase in daily active users within 30 days of launch.” This clarity eliminates ambiguity and makes it simple to interpret experimental results. Without it, you’re just substituting one opinion for another.
Embrace the Minimum Viable Test
The third principle is to build the smallest possible experiment to validate your idea. Often called a Minimum Viable Test (MVT), its sole purpose is to maximize learning with minimal effort. You’re not building a final, polished product; you’re building just enough to get a clear signal from your users.
An invalidated hypothesis is not a failure. It is a valuable, data-backed lesson that prevents you from investing months of engineering effort into the wrong solution. This “fail fast, learn faster” mindset is the engine of innovation.
An MVT could be a simple prototype, a single-feature MVP, or even a landing page to gauge interest. For instance, if you believe users want a new dashboard, you could create a static mockup and measure clicks on the button leading to it. This tiny test provides powerful data on user intent without the massive cost of full development. Catching a bad idea early can save a mid-sized company over $50,000 and months of wasted work.
These principles create a powerful feedback loop. You stop shipping features blindly and start running controlled experiments. Each one sharpens your understanding of what customers truly need, leading to a superior product.
Your Step-by-Step Playbook for Implementing HDD
Making the switch to hypothesis-driven development is about creating a repeatable, structured process for learning. It transforms chaotic brainstorming sessions into a simple four-stage loop that turns vague ideas into value-adding features. Think of it as your team’s engine for continuous improvement.
This framework ensures every development cycle is built on a foundation of evidence, not just enthusiasm. Following these steps builds a habit of questioning assumptions and measuring what matters—the heart of great product development.
Stage 1: Observe and Question
Every strong hypothesis begins with a simple observation. This is where you become a detective, digging into user behavior, market trends, and product data to spot friction points, unmet needs, or hidden opportunities.
- Dig into the data: Analyze your analytics, review heatmaps, and watch session recordings. Where are users dropping off? Which features are being ignored?
- Talk to your users: Conduct user interviews, read support tickets, and analyze feedback forms. What are their pain points and desired outcomes? To learn more about structuring this, check out our guide on how to improve your concept development .
- Scope out the market: What are competitors doing well? What broader industry trends are shaping user expectations?
These observations allow you to frame the problem with powerful “How might we…” questions, setting the stage for a strong hypothesis.
Stage 2: Formulate a Testable Hypothesis
Now, you’ll turn those observations into a formal, testable hypothesis. This single sentence becomes your North Star for the experiment, forcing clarity on what you’re changing, who it’s for, and what you expect to happen.
A strong hypothesis typically follows this formula: We believe that [making this change] for [this specific group of users] will result in [this measurable outcome].
For example: We believe that adding a one-click checkout option for returning mobile customers will result in a 10% increase in completed purchases.
This structure leaves no room for ambiguity. The assumption is clear, the audience is defined, and the success metric is specific.
Stage 3: Design and Run the Experiment
With a clear hypothesis, design the smallest, fastest experiment possible to get a signal. This is about creating a Minimum Viable Test (MVT), not a perfect feature.
Common MVT methods include:
- A/B Tests: Ideal for testing specific changes like button copy, UI layouts, or color schemes on a segment of your user base.
- Phased Rollouts: Gradually releasing a new feature to a small percentage of users (e.g., 5%) to monitor its impact before a full launch.
- Wizard of Oz Tests: Manually performing a feature’s function behind the scenes to simulate the experience and gauge demand before writing any production code.
Building a Minimum Viable Product (MVP) is often a key step in this stage. For a practical guide to building a Minimum Viable Product that effectively tests core assumptions, this resource is invaluable.
Stage 4: Analyze and Iterate
Once the experiment concludes, analyze the data. Did you achieve the success metric defined in your hypothesis? If the data supports your assumption, you can proceed with confidence, rolling the feature out more broadly.
If the hypothesis was invalidated, that’s not a failure—it’s a win. You just learned something valuable and avoided investing heavily in the wrong thing. The next step is to understand why it didn’t work and use that insight to formulate a new, smarter hypothesis. This iterative loop of observing, testing, and learning is what fuels genuine, evidence-based innovation.
How Real-World Teams Use HDD to Win
While the theory is sound, seeing hypothesis-driven development in action is where its power becomes clear. The best product teams build their entire strategy around this constant cycle of experimentation and learning, transforming development from a task list into a discovery engine.
This simple, repeatable process—observe, formulate, experiment, and iterate—is the engine that drives winning teams.
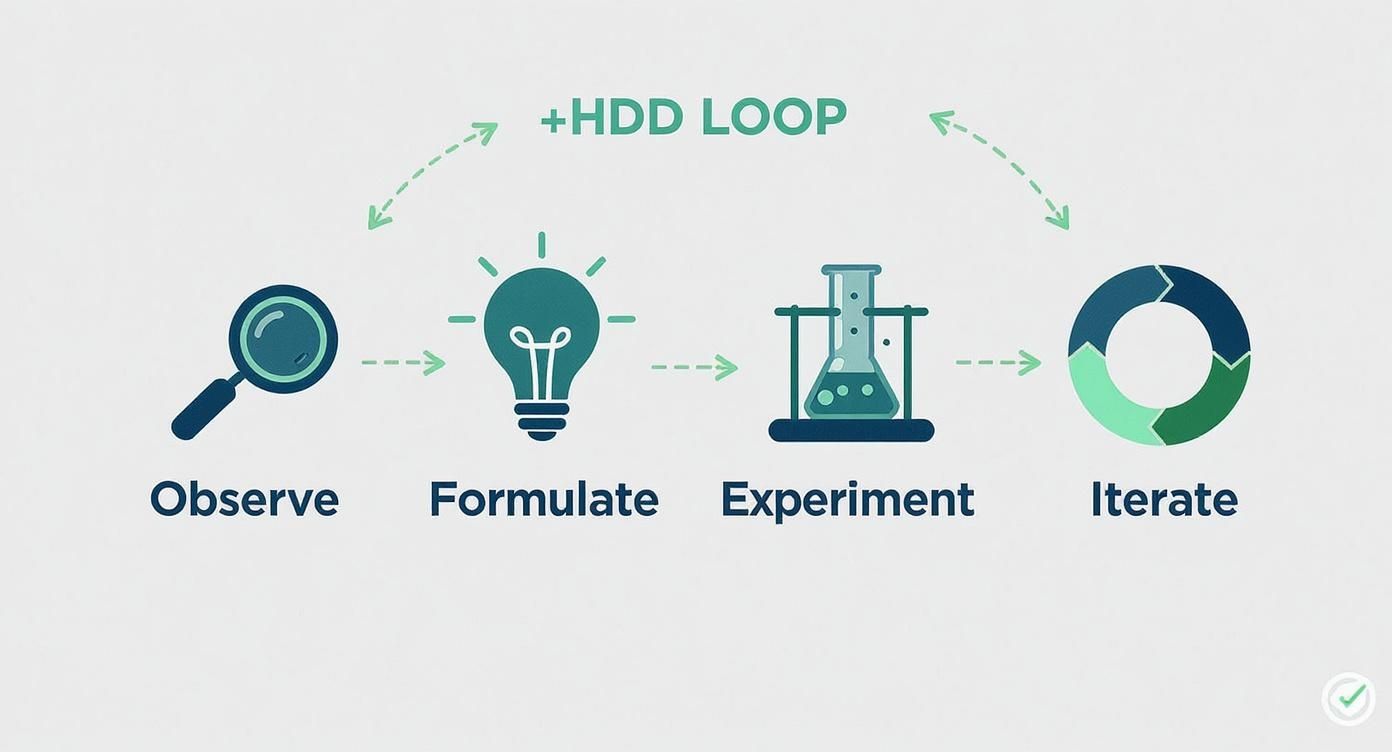
This loop ensures every decision is grounded in evidence, pulling teams away from guesswork and toward genuine, validated learning. Let’s dig into what this looks like on the ground with a few common scenarios.
E-commerce Checkout Optimization
An online retailer observes a high cart abandonment rate on mobile devices, particularly at the final payment step. They suspect their multi-field form is too cumbersome for smaller screens.
- Hypothesis: We believe that implementing a single-click payment option (like Apple Pay or Google Pay) for mobile shoppers will result in a 15% reduction in checkout abandonment.
- Experiment: They run a classic A/B test. 50% of mobile users are shown the new single-click option, while the other 50% see the original form.
- Result: The new flow is a clear winner, reducing abandonment by 18% and slightly increasing the average order value. The data provides a clear mandate to roll out the feature to all mobile users.
SaaS User Retention Feature
A project management SaaS company notices that new teams creating fewer than three projects in their first month are 40% more likely to churn. Their theory is that these users aren’t experiencing the product’s core value quickly enough.
“An invalidated hypothesis isn’t a failure; it’s a valuable lesson that saves you from investing in the wrong direction.”
- Hypothesis: We believe that introducing a guided onboarding checklist that encourages creating three initial projects for new teams will result in a 20% increase in 30-day retention.
- Experiment: They split new sign-ups. Half receive the standard onboarding, while the other half gets the new checklist.
- Result: The experiment only increases retention by 3%, invalidating the initial hypothesis. However, qualitative feedback reveals users loved the idea but wanted project templates to get started. This “failed” experiment pointed them toward a much more effective solution for their next iteration.
AI-Powered Personalization
An AI team wants to boost engagement on its content platform. The current algorithm recommends content based on broad categories. They believe a more personalized approach will increase user stickiness.
For complex AI experiments, tracking the context—the specific model version, parameters, and user segment—is crucial for reproducibility. A tool like the Context Engineer MCP helps maintain this critical context, ensuring that insights from each test are preserved and understood.
- Hypothesis: We believe that using a new collaborative filtering model to generate personalized recommendations for returning users will result in a 10% increase in average session duration.
- Experiment: A controlled segment of users receives recommendations from the new AI model, while a control group sees the old one.
- Result: Average session duration jumps by 12%. The hypothesis is validated, giving the team the confidence to invest the engineering effort required to scale the new model.
Sample Hypothesis Experiments
This table summarizes a few different real-world experiments and their core components.
| Scenario | Hypothesis | Key Metric | Experiment Type |
|---|---|---|---|
| New User Onboarding | Adding a 3-step interactive tutorial will increase feature adoption by 25%. | Feature Adoption Rate | A/B Test |
| Mobile App Navigation | Changing the navigation from a hamburger menu to a bottom tab bar will decrease time-to-task by 30%. | Time on Task | Usability Test |
| Pricing Page Redesign | A simplified, three-tiered pricing page will improve the conversion rate from free trial to paid by 10%. | Trial-to-Paid Conversion Rate | A/B Test |
| AI Chatbot Response | Implementing a persona-driven AI response style will increase user satisfaction scores by 15 points. | Customer Satisfaction (CSAT) | Multivariate Test |
Each row represents a focused, measurable question that a team can answer with data. This disciplined process is how industry leaders stay ahead. You can learn more about how to implement this strategy on ThoughtWorks.com . These examples show that both validated and invalidated hypotheses drive progress, leading to smarter, more impactful products.
The Modern Toolkit for Smarter Experimentation

To effectively implement hypothesis-driven development, you need more than the right mindset—you need the right tools. A modern experimentation stack brings this cycle to life, enabling teams to test ideas, collect clean data, and make evidence-backed decisions.
These tools are the bridge between a brilliant idea and a live, measurable test. They provide the technical scaffolding to ask questions of your users and clearly hear their answers through data. Without them, even the best hypothesis can be derailed by technical roadblocks or unreliable results.
Core Components of an Experimentation Stack
A robust toolkit for experimentation typically integrates several types of platforms, each with a specific role.
-
Feature Flagging Platforms: These are your control levers. Tools like LaunchDarkly or Flagsmith allow you to toggle features on or off for specific user segments without deploying new code. This makes it simple to run an A/B test or gradually roll out a feature to, say, just 5% of your audience.
-
A/B Testing and Optimization Engines: Platforms such as Optimizely and VWO are purpose-built to serve different product variations and determine a statistical winner. They handle the complex statistical analysis, telling you if your results are significant.
-
Product Analytics Tools: To understand user behavior at scale, you need tools like Mixpanel , Amplitude , or Heap . They help you form hypotheses by revealing user friction points and are essential for measuring how experiments impact engagement, conversion, and retention. You can also round this out with qualitative feedback using guides like these client feedback form templates .
The Growing Challenge of Context Drift
As powerful as this stack is, scaling experimentation introduces a significant challenge: context drift. As teams run dozens of tests, the original “why” behind each one—the hypothesis, the user feedback, the chosen metric—becomes disconnected from the code itself.
This is a huge risk, especially for complex products and AI-driven features. A developer might encounter a feature flag in the codebase with no understanding of its purpose, the experiment it served, or the lessons learned. This lost context leads to repeated failed experiments and new features built on unproven assumptions.
A feature flag without its original hypothesis is just technical debt waiting to happen. It’s a remnant of a past decision with none of the wisdom attached.
This is precisely the problem a Context Engineer is trained to solve. Their role is to preserve the “why,” ensuring that the knowledge from every experiment is retained, accessible, and informs future development.
The Context Engineer MCP is a platform designed to automate this process. It integrates with your development environment to automatically link critical context—the hypothesis, requirements, and metrics—directly to the associated code. This creates a living, auditable history of your product’s evolution, ensuring every iteration is built on a foundation of validated learning, not forgotten experiments.
Building a Culture of Continuous Learning
Shifting to hypothesis-driven development is more than a process change; it’s a cultural transformation. It requires moving from a culture where decisions are made by authority or intuition to one that operates on curiosity and evidence.
This mindset fosters a genuine obsession with understanding your users. It becomes an engine that constantly pushes for improvement and smarter innovation. The benefits are clear: you stop wasting months and significant budget on features that fail. Instead, every development cycle, successful or not, becomes a valuable learning opportunity. This is how you build products people love.
Fostering an experimental mindset builds a powerful engine for innovation and creates products that truly resonate with your users. The goal is to make evidence-based decisions the default, not the exception.
So, where do you start? Don’t try to boil the ocean. Pick one small, upcoming feature and reframe it as a simple, testable hypothesis. Define exactly how you’ll measure success before any code is written.
If you need help structuring those initial ideas, check out our guide on how to write product requirements . This single step is the beginning of building a culture of validated learning.
Common Questions About Hypothesis-Driven Development
Let’s address some common questions that arise when teams first explore hypothesis-driven development.
What’s the Difference Between HDD and A/B Testing?
Think of it this way: hypothesis-driven development (HDD) is the overarching strategy, while A/B testing is a specific tactic. HDD is the entire framework for asking smart questions and learning what customers actually want.
A/B testing is a method for running an experiment to get a quantitative answer. So, HDD provides the critical “why” behind an experiment, while A/B testing is one popular way to discover “what” happens as a result.
Is This Just for Big Companies with Tons of Traffic?
Absolutely not. While large companies can achieve statistical significance in A/B tests quickly, the core principle of HDD is about reducing risk—something even more critical for a startup with a limited runway.
Smaller teams can test hypotheses effectively through various methods:
- Qualitative User Testing: Conduct interviews with a prototype to gather direct feedback from a handful of users.
- Beta Testing: Release a new feature to a small, hand-picked group of early adopters.
- Before-and-After Analysis: Compare key metrics from the period just before a change to the period just after to identify significant shifts in behavior.
How Does This Apply to AI and Machine Learning Projects?
HDD is exceptionally well-suited for AI development, which is inherently experimental. It forces a crucial shift from focusing on purely technical metrics (like model accuracy) to the business outcomes that truly matter.
Instead of just aiming to build a “better” model, you frame the work as a business question. For example, a hypothesis might be: “We believe that deploying our new recommendation algorithm will increase average user session time by 10% by providing more relevant content.”
This simple statement directly connects a complex technical effort to a tangible business goal. It’s how you avoid spending months perfecting an AI model that ultimately fails to improve the user experience or drive business results.
Ready to stop guessing and start building with validated learning? The Context Engineering MCP plugs right into your IDE, making sure every AI-driven development cycle is grounded in clear context—from hypothesis all the way to implementation. Start building smarter today .